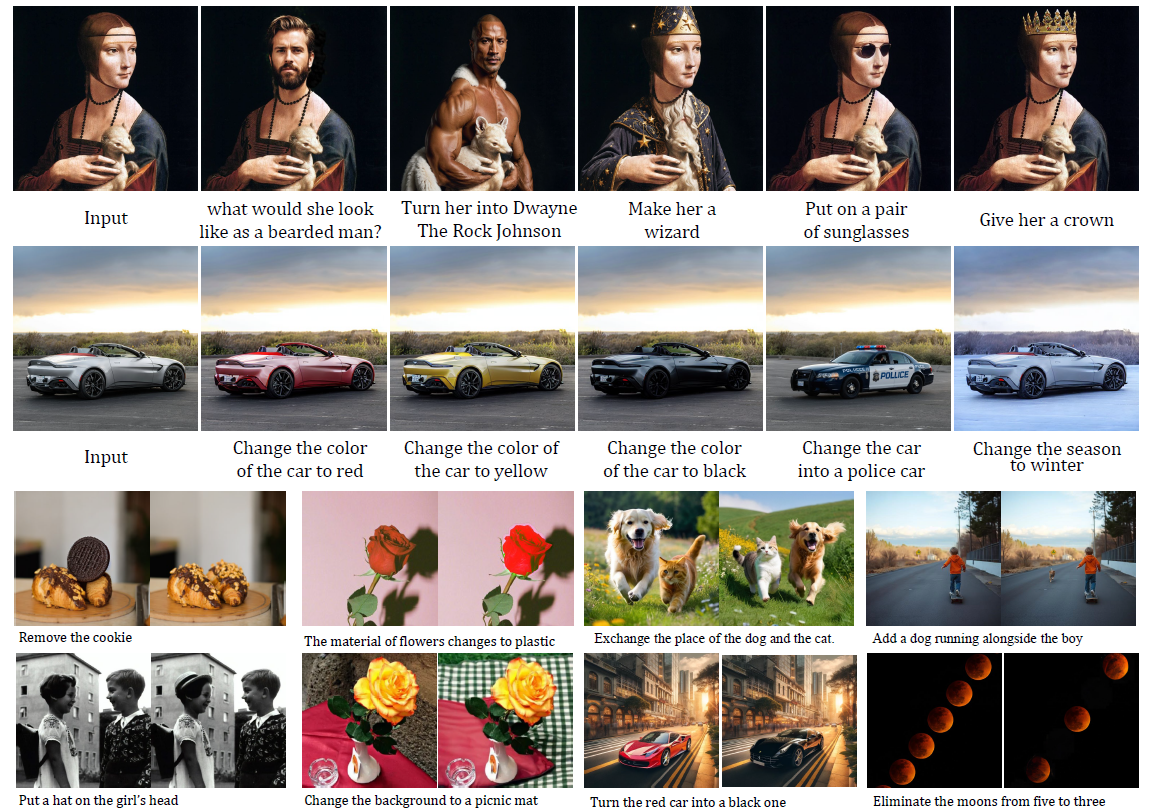
Instruction-based image editing aims to modify specific image elements with natural language instructions. However, current models in this domain often struggle to accurately execute complex user instructions, as they are trained on low-quality data with limited editing types. We present ![]() AnyEdit, a comprehensive multi-modal instruction editing dataset, comprising 2.5 million high-quality editing pairs spanning over 20 editing types and five domains.
AnyEdit, a comprehensive multi-modal instruction editing dataset, comprising 2.5 million high-quality editing pairs spanning over 20 editing types and five domains.
We ensure the diversity and quality of the ![]() AnyEdit collection through three aspects: initial data diversity, adaptive editing process, and automated selection of editing results.
AnyEdit collection through three aspects: initial data diversity, adaptive editing process, and automated selection of editing results.
Using the dataset, we further train a novel AnyEdit Stable Diffusion with task-aware routing and learnable task embedding for unified image editing. Comprehensive experiments on three benchmark datasets show that ![]() AnyEdit consistently boosts the performance of diffusion-based editing models.
AnyEdit consistently boosts the performance of diffusion-based editing models.
This presents prospects for developing instruction-driven image editing models that support human creativity.
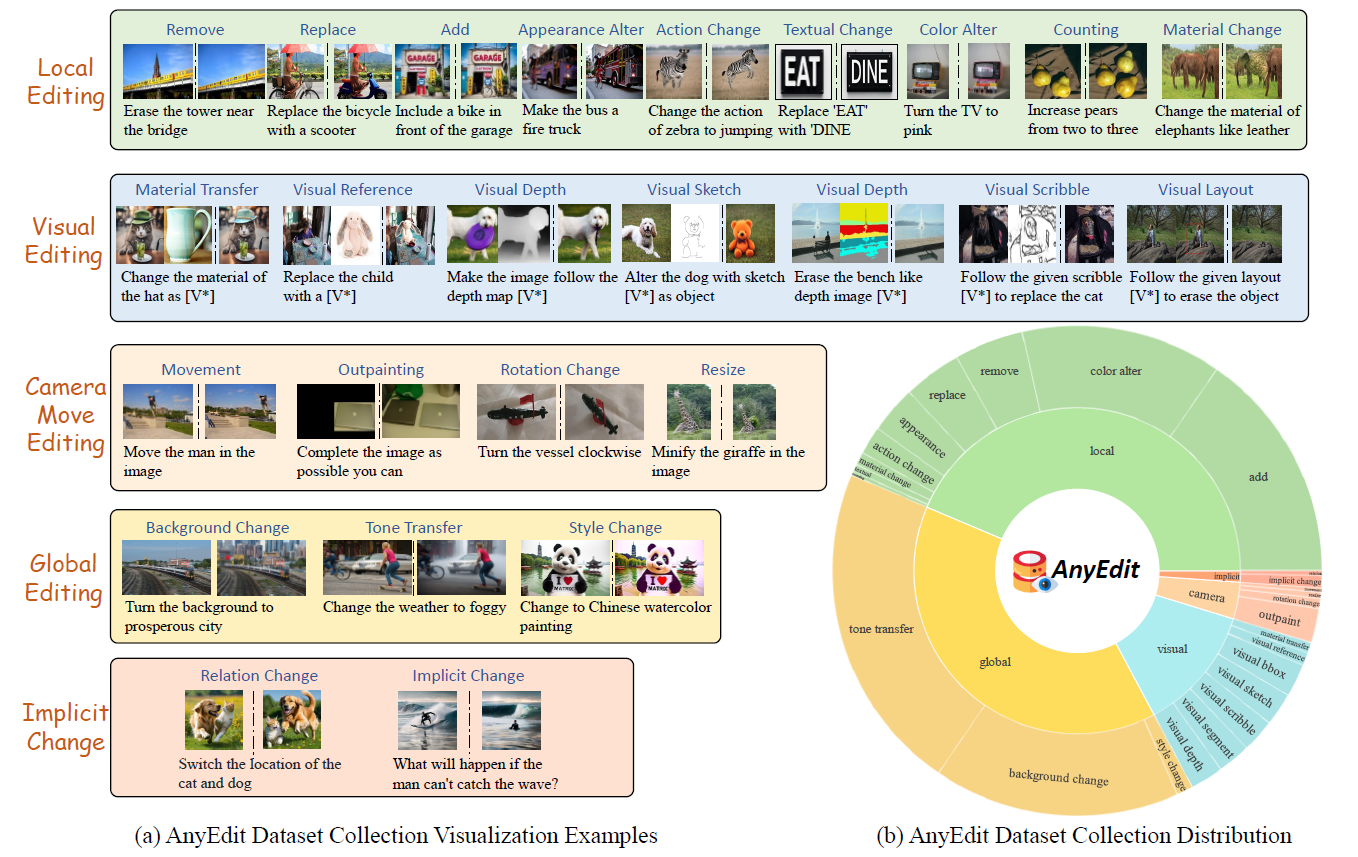
Examples of ![]() AnyEdit at scale.
AnyEdit at scale.
In ![]() AnyEdit, we combine five distinct groups of data, covering 25 editing types, which will be released to help the community. It is worth noting that
AnyEdit, we combine five distinct groups of data, covering 25 editing types, which will be released to help the community. It is worth noting that ![]() AnyEdit is the only dataset that considers the data bias and introduces counterfactual synthetic scenes to balance the distribution of the dataset.
AnyEdit is the only dataset that considers the data bias and introduces counterfactual synthetic scenes to balance the distribution of the dataset.

Subsequently, we invoke off-the-shelf T2I models to produce the initial images. In this manner, we enrich the original dataset by incorporating rare concept combinations, resulting in ∼700K high-quality and diverse image-caption pairs for the ![]() AnyEdit dataset collection.
AnyEdit dataset collection.
Data preparation details for ![]() AnyEdit dataset collection.
AnyEdit dataset collection.
We summarize the general pipeline into five steps:
(1) General data preparation from real-world image-text pairs and synthetic scenes.
(2) Diverse instruction generation using LLM to produce high-quality editing instructions.
(3) Pre-filtering for instruction validation.
(4) Adaptive editing pipeline tailors specific editing methods for each edit type to generate high-quality edited images.
(5) Image quality assessment ensures high-quality editing pairs for the ![]() AnyEdit Dataset.
AnyEdit Dataset.
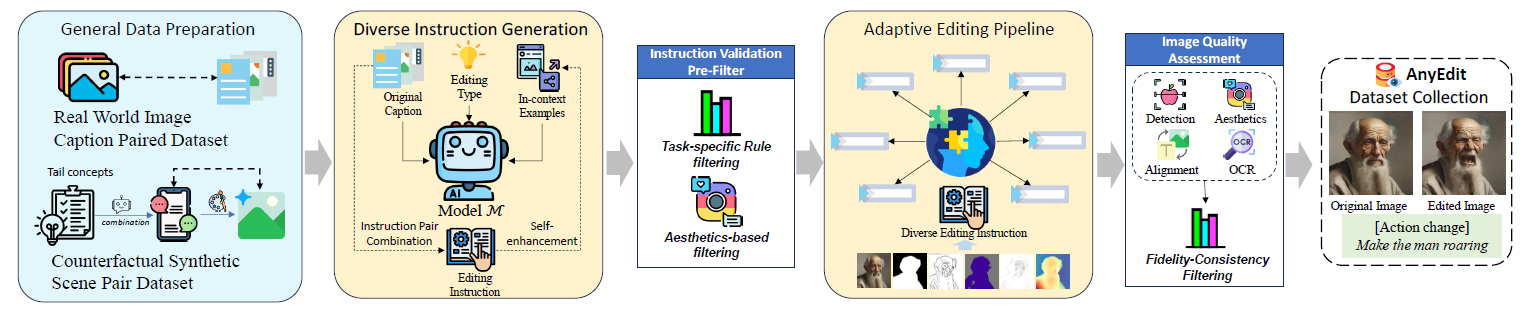
The comprehensive construction pipeline of ![]() AnyEdit.
AnyEdit.












Since ![]() AnyEdit contains a wide range of editing instructions across various domains, it holds promising potential for developing a powerful editing model to address high-quality editing tasks. However, training such a model has three extra challenges:
(a) aligning the semantics of various multi-modal inputs;
(b) identifying the semantic edits within each domain to control the granularity and scope of the edits;
(c) coordinating the complexity of various editing tasks to prevent catastrophic forgetting.
To this end, we propose a novel AnyEdit Stable Diffusion approach (🎨AnySD) to cope with various editing tasks in the real world.
AnyEdit contains a wide range of editing instructions across various domains, it holds promising potential for developing a powerful editing model to address high-quality editing tasks. However, training such a model has three extra challenges:
(a) aligning the semantics of various multi-modal inputs;
(b) identifying the semantic edits within each domain to control the granularity and scope of the edits;
(c) coordinating the complexity of various editing tasks to prevent catastrophic forgetting.
To this end, we propose a novel AnyEdit Stable Diffusion approach (🎨AnySD) to cope with various editing tasks in the real world.
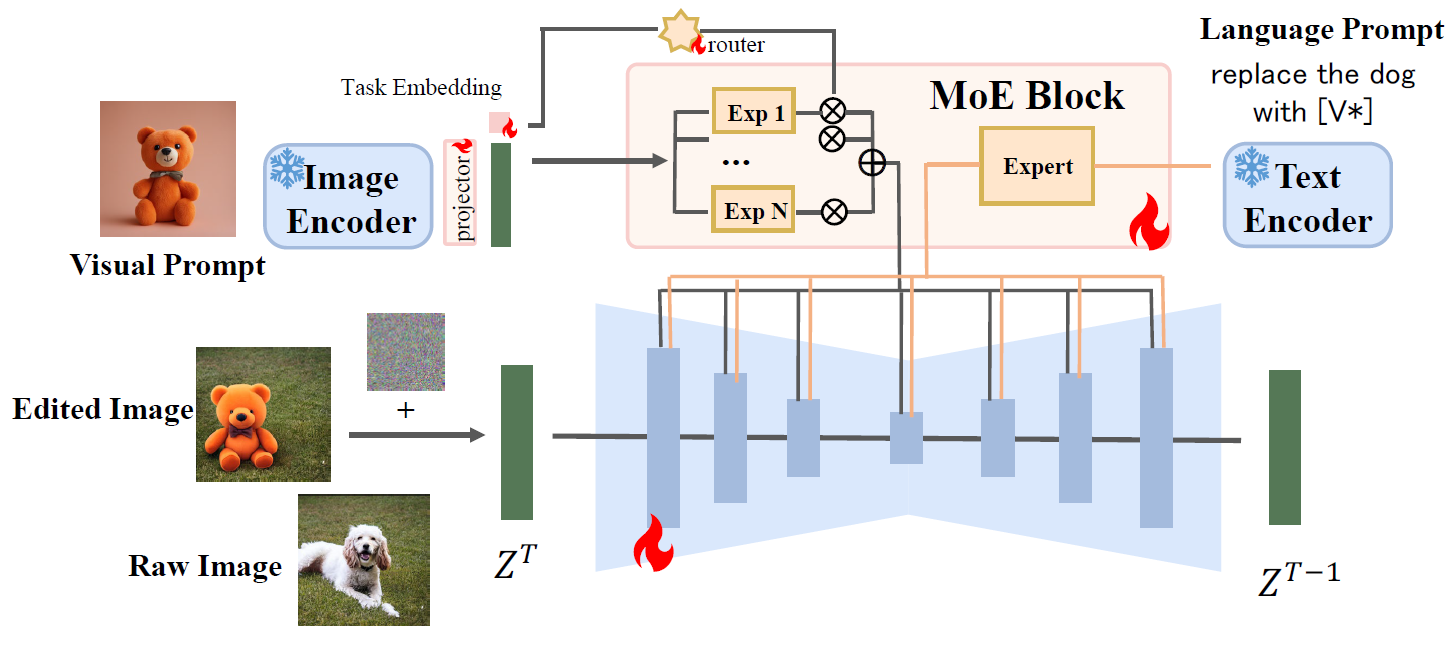
Architecture of 🎨AnySD. 🎨AnySD is a novel architecture that supports three conditions (original image, editing instruction, visual prompt) for various editing tasks.
We report the standard image editing results of ![]() AnyEdit and other baselines on EMU-Edit Test and MagicBrush benchmarks in the table. Based on the experimental results, we have summarized the following conclusions:
AnyEdit and other baselines on EMU-Edit Test and MagicBrush benchmarks in the table. Based on the experimental results, we have summarized the following conclusions:
(i) Our SD-1.5 with ![]() AnyEdit, which only changes the training data to
AnyEdit, which only changes the training data to ![]() AnyEdit, consistently demonstrates superior semantic performance in both edit alignment and content preservation compared to SOTA methods, even without additional mask supervision (0.872 for CLIPim and 0.285 for CLIPout on the EMU-Edit Test). It highlights
AnyEdit, consistently demonstrates superior semantic performance in both edit alignment and content preservation compared to SOTA methods, even without additional mask supervision (0.872 for CLIPim and 0.285 for CLIPout on the EMU-Edit Test). It highlights ![]() AnyEdit's effectiveness in mastering high-quality image editing, validating its high-quality editing data with significant semantic alignment and underlying clear editing structure.
AnyEdit's effectiveness in mastering high-quality image editing, validating its high-quality editing data with significant semantic alignment and underlying clear editing structure.
(ii) Our 🎨AnySD model, trained on ![]() AnyEdit using the 🎨AnySD architecture, further surpasses SOTA methods in both semantic and visual similarity (0.872 of CLIPim on EMU-Edit Test and 0.881 of DINO on MagicBrush Test), setting new records on MagicBrush and Emu-Edit benchmarks.
AnyEdit using the 🎨AnySD architecture, further surpasses SOTA methods in both semantic and visual similarity (0.872 of CLIPim on EMU-Edit Test and 0.881 of DINO on MagicBrush Test), setting new records on MagicBrush and Emu-Edit benchmarks.
This demonstrates the superiority of 🎨AnySD in following editing instructions while preserving unchanged image elements, thanks to its task-aware architecture that learns task-specific knowledge from the diverse editing types in ![]() AnyEdit, enhancing the model's cross-task editing capabilities.
AnyEdit, enhancing the model's cross-task editing capabilities.
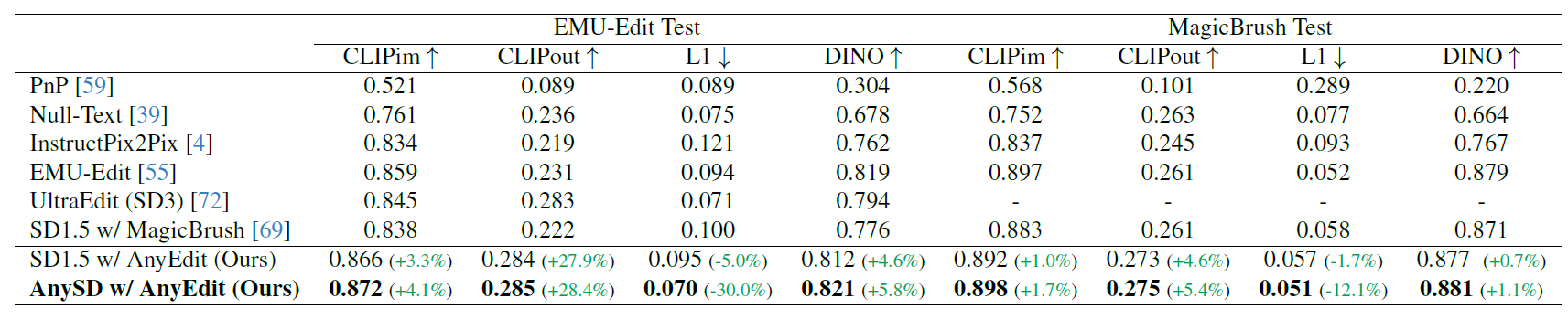
Comparison of methods on EMU-Edit and MagicBrush benchmark. We show performance improvements
over SOTA models of the same architecture, with only training data differences.
Below Table presents the results of the ![]() AnyEdit-Test benchmark, where each instruction is designed to rigorously evaluate
AnyEdit-Test benchmark, where each instruction is designed to rigorously evaluate ![]() AnyEdit’s adaptability across a wider range of challenging editing scenarios. We provide further results of each editing category in Appendix F. It can be observed that
AnyEdit’s adaptability across a wider range of challenging editing scenarios. We provide further results of each editing category in Appendix F. It can be observed that
(i) most baselines struggle to effectively handle more complex editing tasks that are rarely in standard benchmarks (0.190 v.s. 0.121 on average L1), especially for implicit editing that requires reasoning abilities. This illustrates the importance of ![]() AnyEdit-Test for evaluating the performance of editing models on complex tasks.
AnyEdit-Test for evaluating the performance of editing models on complex tasks.
(ii) Even for common editing tasks, state-of-the-art models show a significant decline in consistency performance on ![]() AnyEdit-Test (-3.5% on CLIPim and -19.2% on DINO of UltraEdit). This underscores the limitations of existing benchmarks in evaluating multi-scene editing.
AnyEdit-Test (-3.5% on CLIPim and -19.2% on DINO of UltraEdit). This underscores the limitations of existing benchmarks in evaluating multi-scene editing.
(iii) In contrast, ![]() AnyEdit significantly outperforms SOTA methods across all editing categories, demonstrating its scalability and robustness in handling complex tasks across diverse scenarios.
AnyEdit significantly outperforms SOTA methods across all editing categories, demonstrating its scalability and robustness in handling complex tasks across diverse scenarios.
(iv) Traditional methods often struggle to handle visual editing effectively due to additional visual inputs. In such cases, even when compared to Uni-ControlNet, which is pre-trained with diverse visual conditions, ![]() AnyEdit consistently performs better in visual editing tasks. It shows the efficacy of
AnyEdit consistently performs better in visual editing tasks. It shows the efficacy of ![]() AnyEdit in handling vision-conditioned editing instructions.
AnyEdit in handling vision-conditioned editing instructions.

Comparison of methods on ![]() AnyEdit-Test benchmark
AnyEdit-Test benchmark




















@article{yu2024anyedit,
title={AnyEdit: Mastering Unified High-Quality Image Editing for Any Idea},
author={Yu, Qifan and Chow, Wei and Yue, Zhongqi and Pan, Kaihang and Wu, Yang and Wan, Xiaoyang and Li, Juncheng and Tang, Siliang and Zhang, Hanwang and Zhuang, Yueting},
journal={arXiv preprint arXiv:2411.15738},
year={2024}
}